Software simulation plays a crucial role in the development of hardware systems and microarchitectures. To ensure that chip designs meet established requirements, developers typically analyze and verify all aspects of the architecture. In this context, software simulators, facilitated by software tools, are often more effective than hardware languages. The high degree of flexibility offered by software languages enables the efficient implementation of hardware models, as well as debugging and verification of their design. Moreover, software simulators are significantly more efficient than hardware emulators, enabling substantial time savings in the development process.
However, software simulation can be biased depending on the specific requirements. Different software simulators prioritize different designs, striking a trade-off between performance and accuracy. For complex workloads, balancing efficiency and accuracy poses significant challenges to mainstream simulators, which limit their utility in analyzing complex programs.
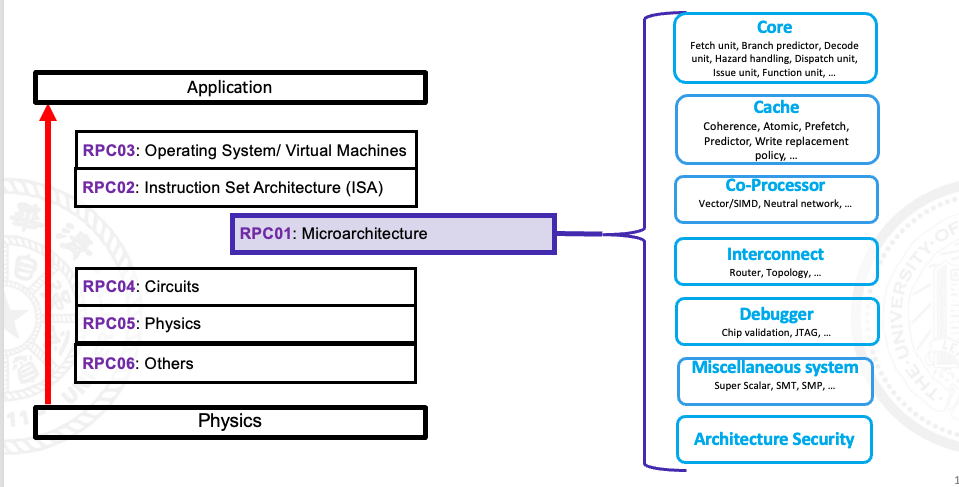
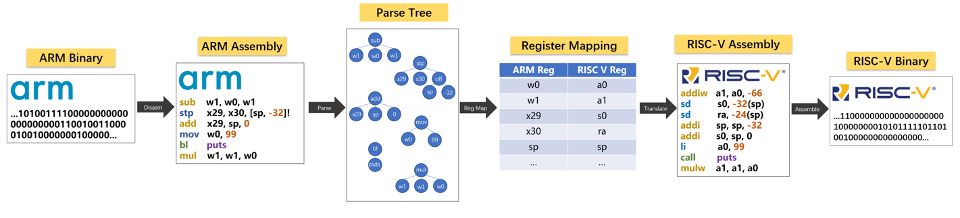
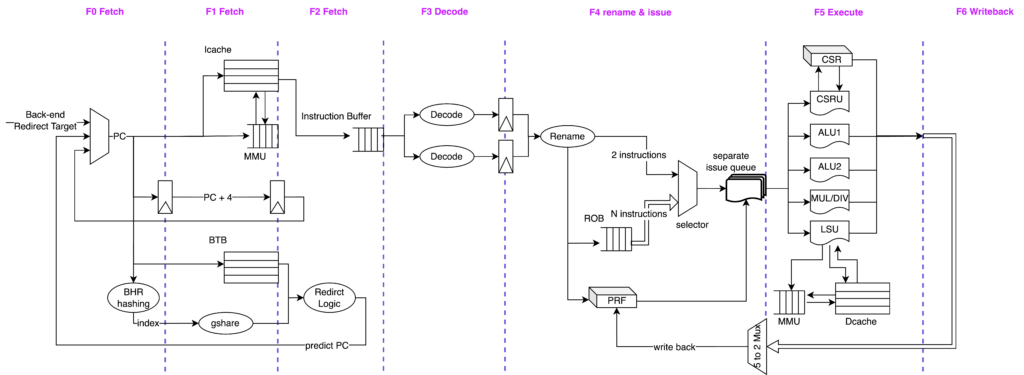
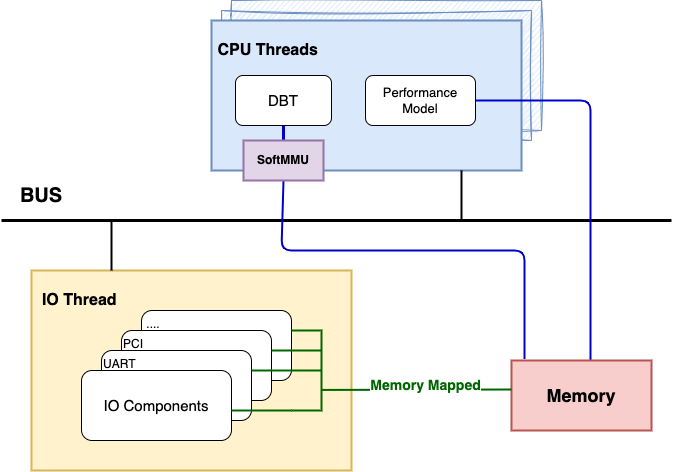
This thesis proposes a full-system cycle accurate software simulation framework, (Name), based on QEMU platform. The framework connects the CPU performance model to the virtual System-of-Chip (SOC) via a bus, allowing for the support of complex IO devices while accurately simulating cycle-level instructions. Furthermore, this thesis proposes a dynamic CPU model switching mechanism, which enables architects to switch between functional implementation and timing simulation in real-time, providing high flexibility and configurability to suit specific simulation accuracy requirements.
To demonstrate the effectiveness, we implement a case study based on the RISC-V Instruction Set Architecture (ISA). This includes an out-of-order CPU model, memory model, and common IO devices. Using this implementation, we conduct experiments on some complex benchmarks, and demonstrate the superiority of our simulator through experimental data and comparisons with mainstream simulators.